F# Data Type Providers in .Net Core


As one of F#'s killer features; type providers have the ability to make rooms full of developers gasp when shown for the first time.
Support has recently been added to the FSharp.Data library for .Net Standard 2.0, allowing us to use type providers for a range of formats with .Net Core. With that in mind, let's explore what this feature is all about.
Type Providers are a way of generating static types that are consistent and verifiable at compile time whilst still being dynamically built.
To demonstrate what I mean by that, let's start with this JSON file:
[
{
"Id": 2,
"FirstName": "Bob",
"LastName": "Baggins",
"Hobbies": [
"Mountain Biking",
"Gaming",
"Music"
]
}
]
In most statically typed languages like C# and Java we'd start consuming this JSON by building a model:
using System.Collections.Generic;
namespace DataTypeProviders.CsharpVersion
{
public class SampleModel
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public List<string> Hobbies { get; set; }
}
}
Then we'd deserialise the JSON into this predefined model:
var json = File.ReadAllText(JsonFile);
var contents = JsonConvert.DeserializeObject<List<SampleModel>>(json);
foreach(var person in contents)
{
Console.WriteLine($"Loaded {person.FirstName} - {person.LastName}");
}
The advantage of building the model is that it is clear in our code what to expect when consuming the raw JSON.
The disadvantage however is we have to maintain that model, keeping it up to date if the JSON schema changes. It can also be brittle as, if the schema changes and we forget to update the model, the application can error at run-time.
Another disadvantage comes when working with more complex models, such as large XML documents. Maintaining a class representation of the schema can become cumbersome and time consuming.
You could instead dynamically consume the JSON, commonly done in languages like Python or JavaScript, like so:
with open(json_file) as f:
contents = json.load(f)
for person in contents:
print(f"Loaded {person['FirstName']} - {person['LastName']}")
This removes the need to predefine the model, however as the model is implicit it can be difficult working out both the names and types to refer to when loading the JSON. It is also just as brittle; the schema can still change, breaking the code.
Now let's see how you would do this with F# type providers:
Firstly, we need the FSharp.Data NuGet package. At the time of writing (24/04/2018) .Net Standard 2.0 support is available in the beta version of the package.
We're going to be using the JSON Type Provider from this library, docs for which can be found here.
With the dependency added we can now load the json like so:
open FSharp.Data
open System.IO
type Sample = JsonProvider<"./Sample.json">
let content = Sample.Parse(File.ReadAllText(jsonFile))
for person in content do
printfn "Loaded %s - %s" person.FirstName person.LastName
Note how we've not added an explicit model like we did in the C# version. So you may be thinking "OK, so it's like the Python version, it's evaluated at run-time". You would however be wrong, and here's where the magic happens:
Behind the scenes what the type provider at compile time is:
- Reading the file you've provided
- Working out what keys and types are in the file
- In our example, it will see the "Id" key and work out based on all occurrences of it in the provided file that it is an integer
- Dynamically generating a type for the file across all keys and possible type permutations
- Passing that type to the compiler like any normal class you've declared
This provides us with two really interesting advantages. Firstly; you get intellisense providing the names and types of the json file you are consuming, without actually having to build a model first:
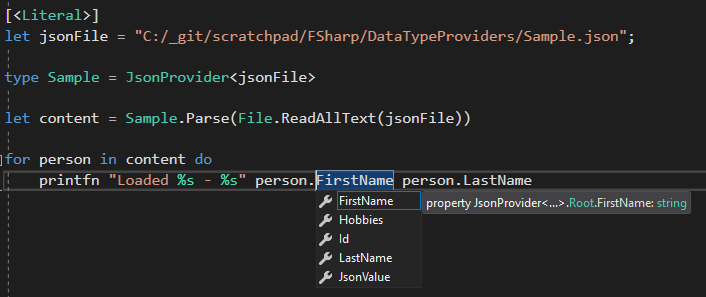
Secondly it means that if the schema in the Sample.json file changes our code will fail at compile time with build errors. This includes if the type changes, or multiple types are stored under the same property. For example, let's update the source json to:
[
{
"Id": 2,
"FirstName": "Bob",
"LastName": "Baggins",
"Hobbies": [
"Mountain Biking",
"Gaming",
"Music"
]
},
{
"Id": "jim.bob",
"FirstName": "Jim",
"LastName": "Bob",
"Hobbies": []
}
]
The "Id" key can now be either an integer or a string, which is now reflected in the generated type:

Any usage before that assumed the Id was an integer would break, allowing us to catch the bug at compile time, rather than run-time. We can then access the value like so:
for person in content do
match person.Id.Number with
| Some id -> printfn "Has integer id %i" id
| None -> ()
match person.Id.String with
| Some id -> printfn "Has string id %s" id
| None -> ()
All of this is pure magic to me; I've found it especially useful when exploring new data sets, allowing for a rapid understanding of the structure of the data. It is also franky invaluable when dealing with overly complex response objects (I'm looking at your ElasticSearch) that become onerous to map by hand.
To find out more you can read the F# Data Library docs here. Here's hoping the .Net Standard 2.0 support comes out of pre-release soon!